



It can recognize your voice and talk in a range of human-like voices.
VOICE STUDIO is a high-quality voice recognition and voice synthesis studio that can be used in a variety of voice-based businesses. Accurate speech recognition and human-like natural speech synthesis technology enable seamless communication between people and AI.
- #AI consultation extension
- #Automatic subtitle generation
- #Voice-based virtual assistant
- #Voice search
- #AI voice recording
- #AI human


What makes VOICE STUDIO so special?
VOICE STUDIO provides high-quality voice recognition and synthesis service with only a small amount of domain data training through the built-in general model with more than 10,000 hours of training.
-
Point 01
Speech recognition rate of 95.6%
and natural synthesis

-
Point 02
Real-time voice recognition of
streamed content

-
Point 03
5 minutes worth of speaker identification
every second

-
Point 04
Transfer learning-based
speech synthesis

-
Point 05
One-click integrated
management tool

System Configuration

Core Technology
Real-Time STT
Real-time voice recognition boasting a 95.6% accuracy
VOICE STUDIO's voice recognition engine can be used for a variety of real-time voice services based on the voice interface. And faster and more accurate voice recognition can be achieved through end-to-end integrated learning, moving away from traditional language models, sound models, pronunciation dictionaries, etc. that are trained individually.

Features
-
01High performance base model with over 10,000 learning hours
To ensure adequate performance in domains with less data, we offer a high-performance baseline model trained using approximately 10,000 hours of reliable 8kh/16kh data.

-
02End-to-end real-time streaming speech recognition technology
The Streaming Transformer Voice Recognition technology is applied to process voice recognition in real time, enabling natural conversation processing.

-
03Speaker identification engine
Equipped with an i-Vector-based speaker identification engine, it is possible to process 5 minutes of voice data every second when operated in batch.

-
04One-click integrated management tool
We offer tools to handle voice learning, model construction and arrangement, verification, as well as services that can be used with only a few clicks, even if you are not a specialist in development.

Realistic TTS
Voice synthesis that creates real human-like voice
VOICE STUDIO's voice synthesis engine artificially creates a human voice through a voice model that is trained using text. The deep learning-based end-to-end transfer learning technology, in particular, enables high-quality speech synthesis using only a small amount of data.

Features
-
01Adaptive learning-based speech synthesis technology
You can create a business-grade voice TTS in the style preferred by the client by fusing a small quantity of voice data of the desired style with existing voice data using the transfer learning-based speech synthesis model.

-
02Voice synthesis with 30-minute audio data
Using deep learning-based end-to-end transfer learning, high-quality voice synthesis of the target entity is now achievable with far less learning data than the current speech segment synthesis approach.

-
03Domain-specific Hangul text conversion
In order to generate pronunciation for various non-Hangul words, our technology provides non-Hangul notation (numbers, foreign words, abbreviations, etc.) and English phonetic alphabet conversion to provide smooth voice synthesis.

-
04One-click integrated management tool
A voice synthesis model may be easily created using the management tool, and transfer learning is provided to incorporate limited data into existing models.

VOICE STUDIO TOOL
Professional tool for voice recognition and synthesisVOICE STUDIO provides key features for voice service implementation, from voice recognition/synthesis model building to distribution and management.
-
Data management

-
Learning management

-
Verification management

-
Pre-management

-
End point management

-
History management

Tool Introduction
-
01Voice recognition Manage
-
Voice recognition engine for real-time streaming
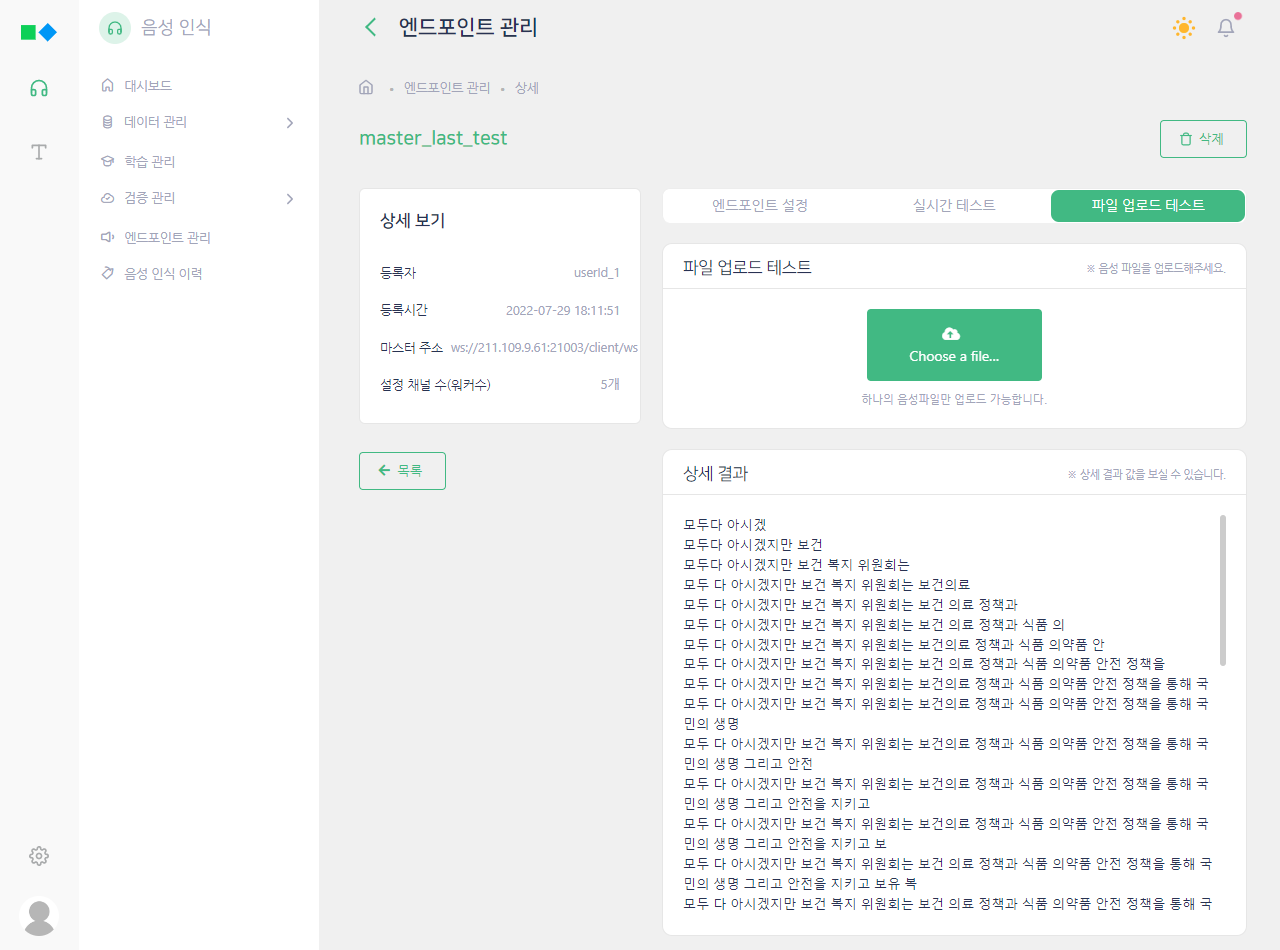
- Streaming transformer-based real-time speech recognition model
- Connected learning through domain data
- Register user vocabulary in real time
- Manage voice recognition history inquiry with the management tool
- Manage voice recognition learning data and voice recognition models
- Verify voice recognition model
- Monitor voice recognition server and manage resource
-
-
-
02Speech synthesis
-
Create voice synthesis models and offer transfer learning function that merge small data with existing models
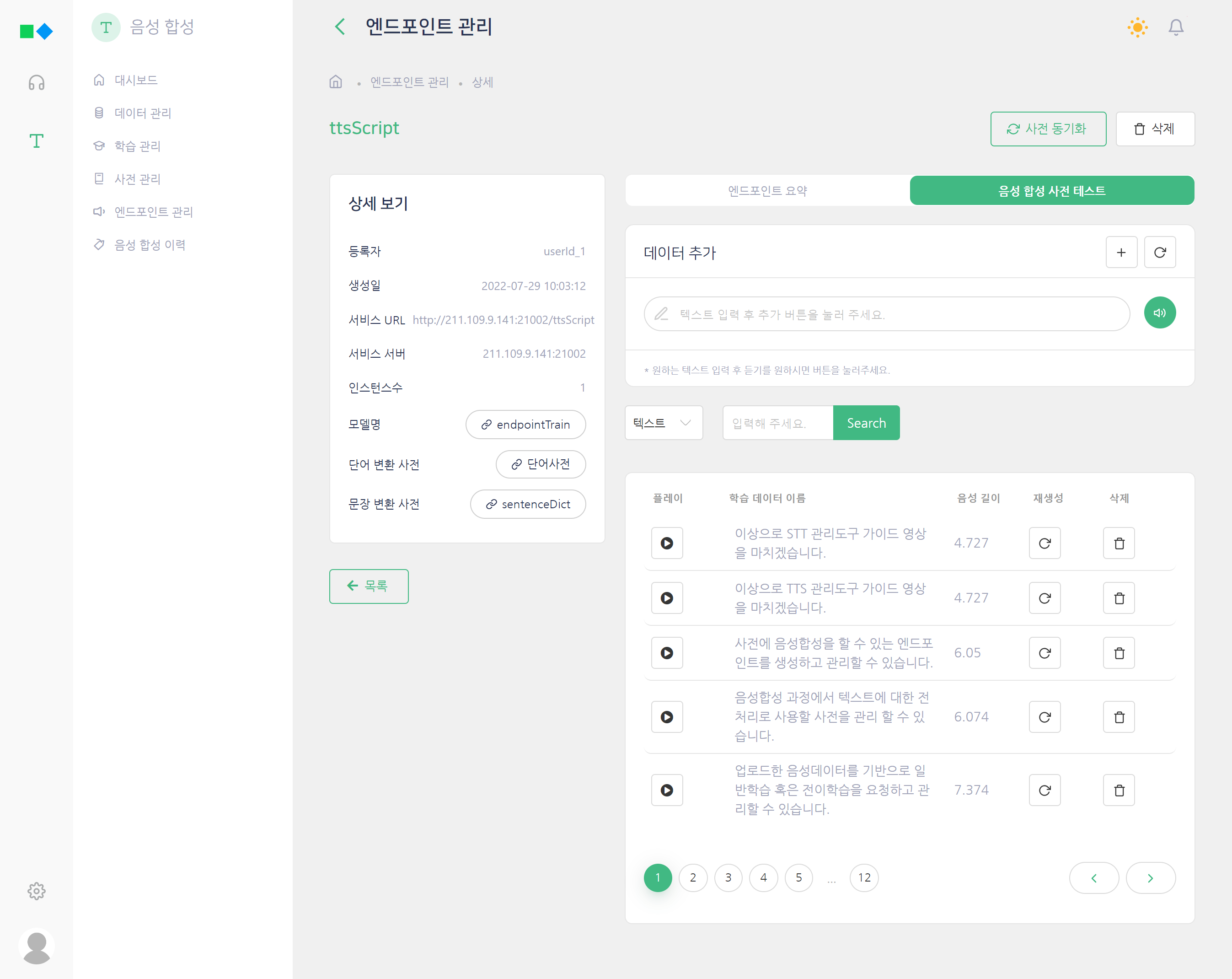
- Upload and manage transcription and voice data
- Edit meta information of learning data
- Manage sentence and word dictionaries for speech synthesis
- Monitor voice learning performance in real time
- Manage transfer learning status
- Monitor voice synthesis server and manage resources
- Manage voice synthesis processing history
-
-
-
03Voice transcription
-
Learning data for implementing voice recognition/synthesis model specific to each domain
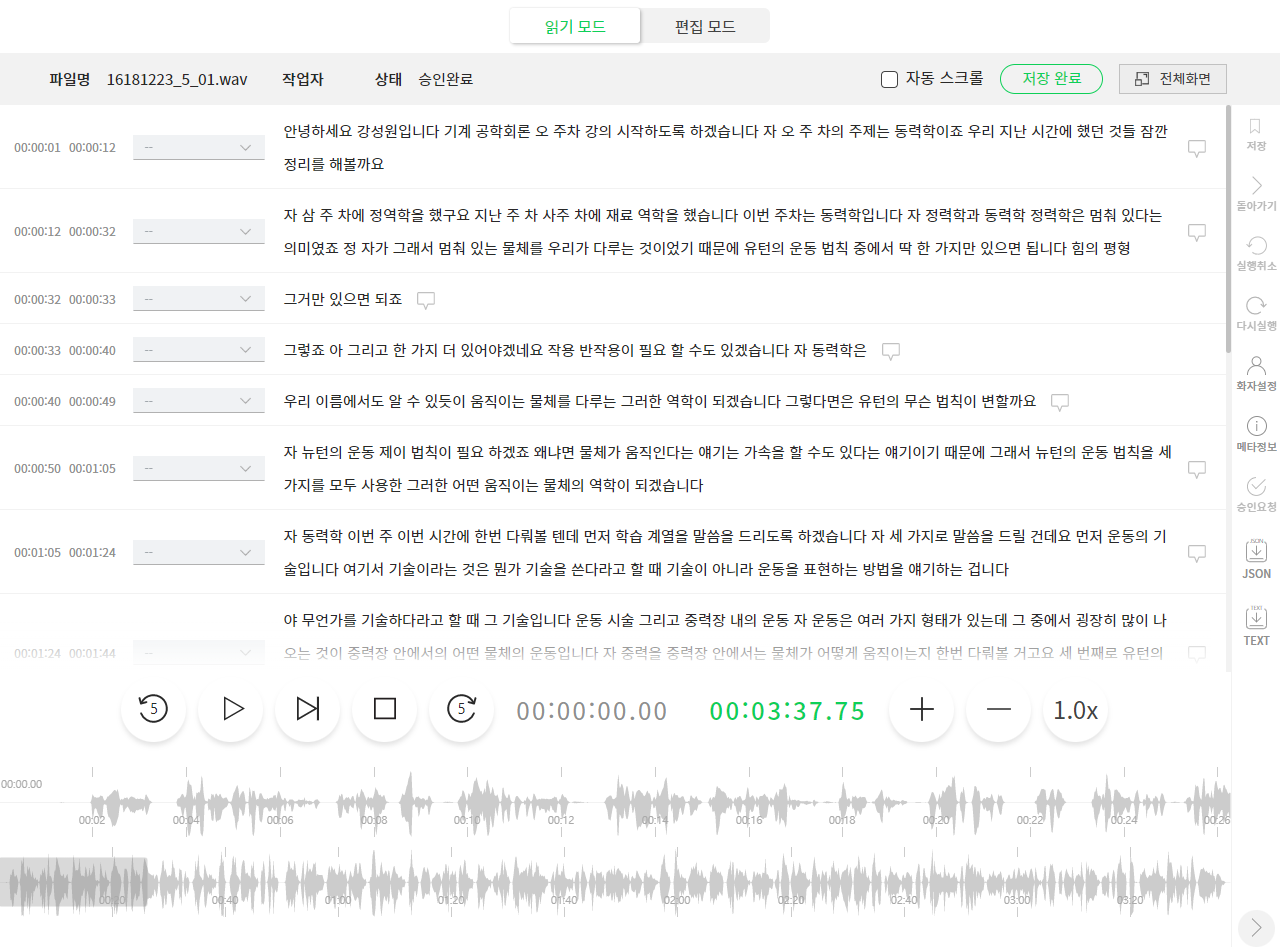
- Integrated monitoring for work stages
- Upload voice audio files and create pre-texts
- Manage transcription set per domain
- Work management function for each task officer
- Inspect and approve work deliverables
- Authorize workers with user authorization management
-
-
Success Story
-
AI metahuman (METAHUMAN)
LGU+ “U+Kids Land” AI project Digital human, “AI Garami”
Two AI children, digital AI human Garami who learned refined children's content while the other learned any video content, regardless of its target audience's age.
Watch video -

- Received the ‘2020 Korea Advertising Awards’ for creativity, public interest, and educational accomplishments through AI experiments
-
National Assembly Secretariat
National Assembly Internet broadcasting business AI live meeting subtitle system
Established a demonstration system for live broadcast subtitles with Al voice recognition on the parliamentary telecast to strengthen accessibility of disabled people's activities in accordance with the revision of the National Assembly Act (2020.12.22)
-
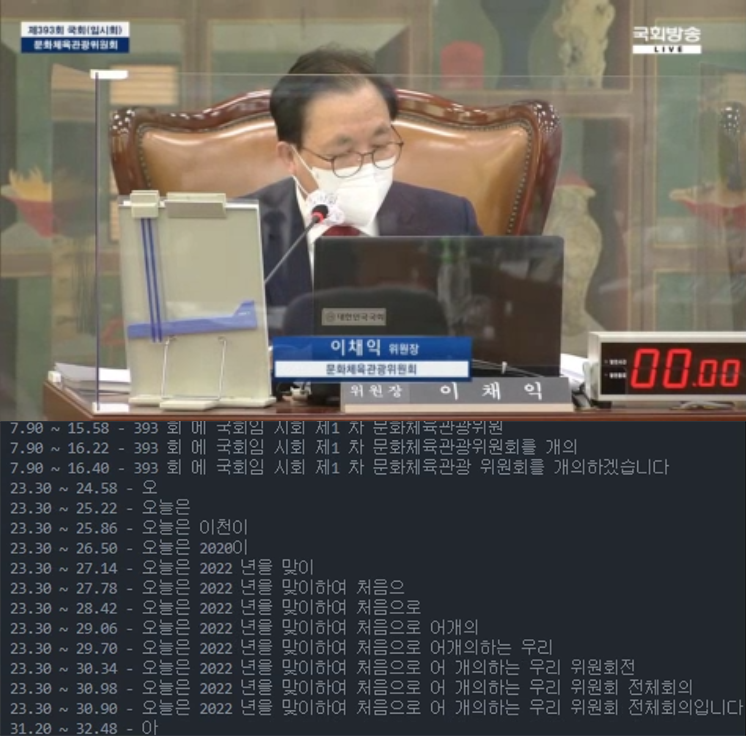
- Implemented intelligent parliament and enhanced public access to information on legislative activities
-
Outbound AI voice bot
Automate outbound call center AI voice bot utilization
Automated counselors’s tasks such as automatic notification of customer's delinquency, essential notice guide or beneficiary certificate happy calls through outbound callbots.
-

- Improved the quality of consultation by improving the quality of consultation and providing knowledge information that has been verified.
-
AI voice bot
AI chatbot combining advanced deep learning technology with 1st gen customer chatbot.
Utilized voice synthesis for contact center announcements and MRC technology to deliver natural speech services and respond to unanswered queries in currently existing chatbots.
-

- Provided optimal answers to queries that were challenging to answer, increasing chatbot satisfaction and usage at the same time, and offering voice services without heterogeneity.
Reference
-
AI-based consultation booth
Credit Counseling and Recovery Service
Civil AI counseling system on debt settlement

-
AI customer voice bot
NH Nonghyup Bank
Korea's first real-time remote AI callbot service in the finance contact center

-
Outbound AI voice bot
NH Nonghyup Bank
Automate outbound call center AI voice bot utilization
-
Outbound AI callbot
Korea Investment & Securities
AI-based customer support callbot and work chatbot system for employees

-
Internet Broadcasting System
National Assembly of the Republic of Korea
Live broadcast subtitles with Al voice recognition for parliamentary telecast

-
AI voice system for civil services
Daejeon Metropolitan City
Smart Mirror, AI voice recognition system for civil services

-
AI human - Pyongyang Friend
Ministry of Unification
A virtual friend from Pyongyang, trained with North Korean information and voices such as people's speech and intonations.

-
Remote digital human civil complaint service
Gwangju Metropolitan City
Digital human version of the Mayor of Gwangju

-
Voice of degenerative brain disease patients
National Information Society Agency
AI learning data building tool for collecting voices of patients with degenerative brain disease

-
Voice data by subject matter
National Information Society Agency
Over 10,000 hours of broadcast data, over 7,000 hours of conference-related audio
-
Dialogic AI data of broadcast content
National Information Society Agency
17,000 hours in total of broadcasting content used for voice transcription learning data.
-
Korean dialect AI data
National Information Society Agency
15,000 hours in total, 2.5 million sentences Learning data of regional dialect transcription