



Customized language model platform essential for various AI services
The LANGUAGE STUDIO makes it easy to build domain-specific language model thanks to its user-friendliness and reduced complex coding. Create custom language models for various fields such as finance or law, for both public and private institutions.
- #Super-large language model
- #Large-capacity language analysis
- #Intent classification
- #Emotion/sentiment analysis
- #Learning data construction
- #Similarity analysis


What Makes LANGUAGE STUDIO So Special?
LANGUAGE STUDIO lets anyone create large language models that can be easily optimized for each domain.
-
Point 01
High-quality natural language
on deep learning

-
Point 02
Seamless domain
application

-
Point 03
6 specialized transfer
learning models

-
Point 04
Direct creation and
GUI-based language

System Configuration

Core Technology
Pre-training
Supermassive language model that enables language understanding
Create your own model using specialized language templates pre-trained with jargon gathered from large domain-specific learning data. Our large-scale language template models can be used for a variety of natural language processing.

Features
-
01High-quality natural language processing based on deep learning
High-quality natural language processing is achievable with the use of the most recent machine learning and deep learning (artificial neural network) technologies, which provide faster and greater performance than the existing techniques.

-
02Seamless domain application
By using dictionaries and rules that are specific to each domain in addition to common dictionaries, it offers language models according to language characteristics of various fields and allows functions to create vast volumes of learning data individually.

-
03Latest super-large language models available
BERT, ELECTRA, and RoBERTa are just a few of the models Saltlux offers, along with a proven model with up to 350 million parameters. Saltlux also give an ultra-large language model that has been trained with over 100G of data in order to create a domain-specific language model.

Fine-tuning/transfer learning
A language model that addresses various domain-specific needs
Through pre-learning model-based transfer learning, our technology learns various tasks (text classification, sentence embedding, named entity recognition, morpheme analysis), and evaluates quality using our template models in order to provide the optimal, best performing model for your needs.

Features
-
01Text classification
It categorizes text entered into a predefined class, allowing you to arrange everything from simple sentences to complex documents.

-
0202 Sentence embedding
With the sentence embedding method that not only understands the meaning of a sentence, it also finds similar sentences.

-
03Named entity recognition
It provides a user-defined object recognition model from input text, thus enabling information retrieval and object name recognition for interactive systems that requires high accuracy.

-
04Morpheme analysis
It provides analytic results in 'morphemes', the smallest semantic unit of phrases, allowing the restoration of adjectives and verbs to their original forms, and directly modifying the outcomes using lexicographic functions.

-
05Emotion, sentiment analysis
It categorizes the emotions and sentiments of text, providing a model that categorizes positive/negative sentences and the emotional state of the counterpart.

-
06Intent analysis
It analyzes the meaning of the sentence, classify its intent and offers a specialized model that understands user intention in conversations.

LANGUAGE STUDIO TOOL
Specialized tools for the implementation of comprehensive custom language models by domainLANGUAGE STUDIO provides key features for text service implementation, from the development of learning models to their deployment and management.
-
Learning data management

-
Model learning

-
Model arrangement

-
Model management

-
Labeling tool

Tool Introduction
-
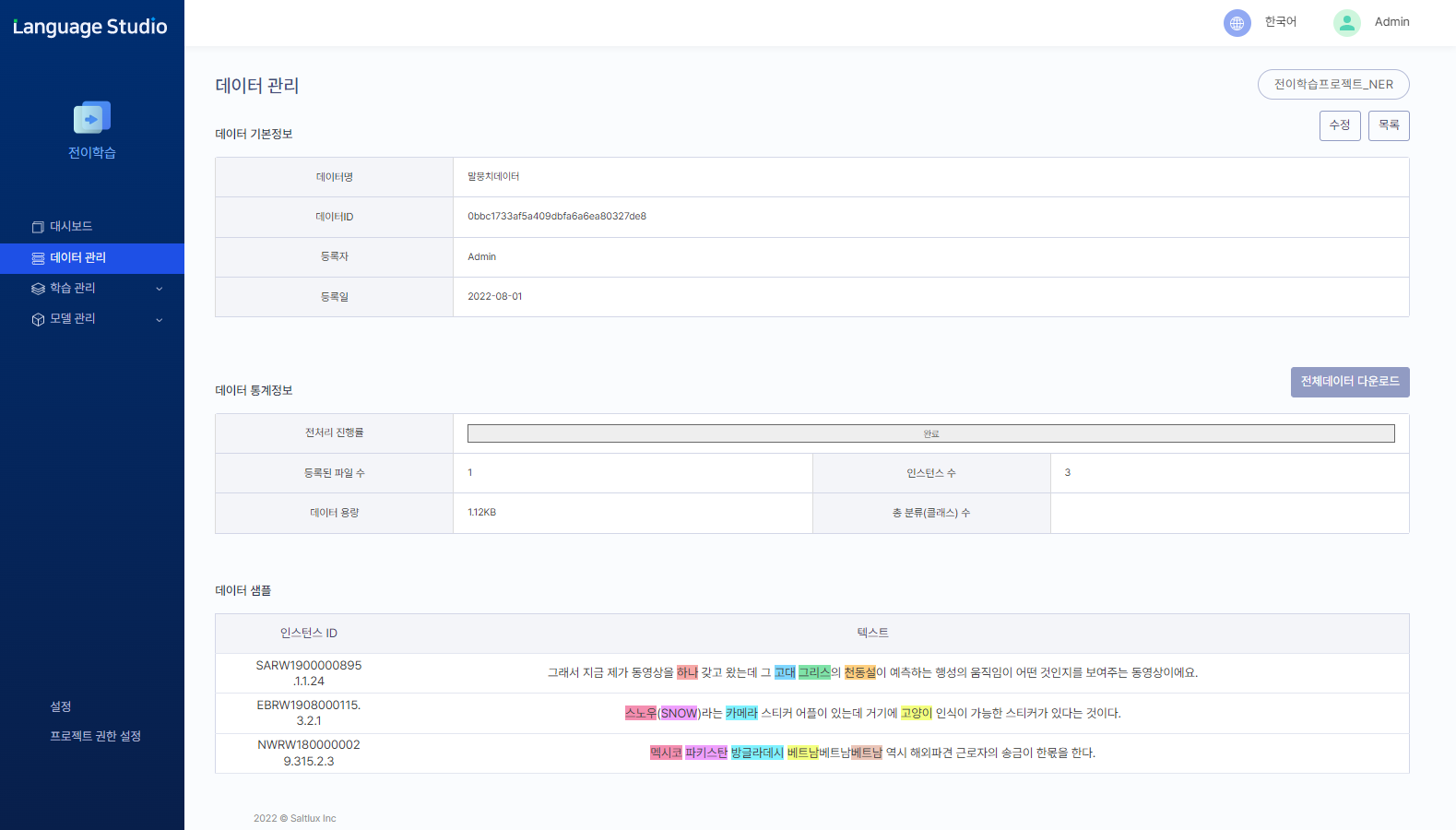
01Learning data management
-
Provides integrated management of large volumes of pre-training data and learned data by various domains
- Upload/download JSON files
- Data pre-processing
- Data statistics processing
- Data sampling
-
-
-
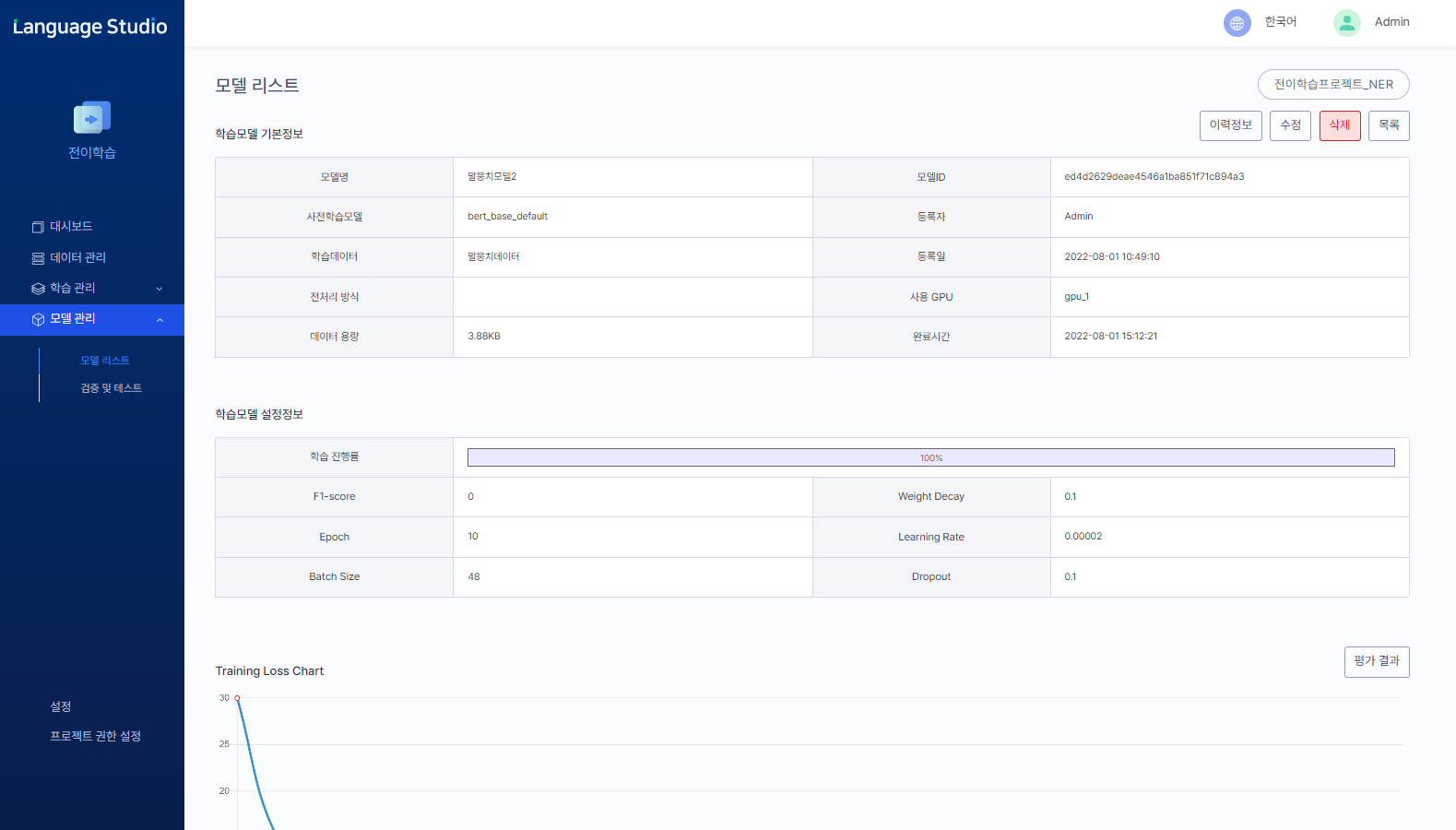
02Model learning
-
GUI-based model learning
- Latest super-large language models available
- Learning with multi-GPU
- Merge learning data and provide statistics
- Check learning status of models and loss curves
-
-
-
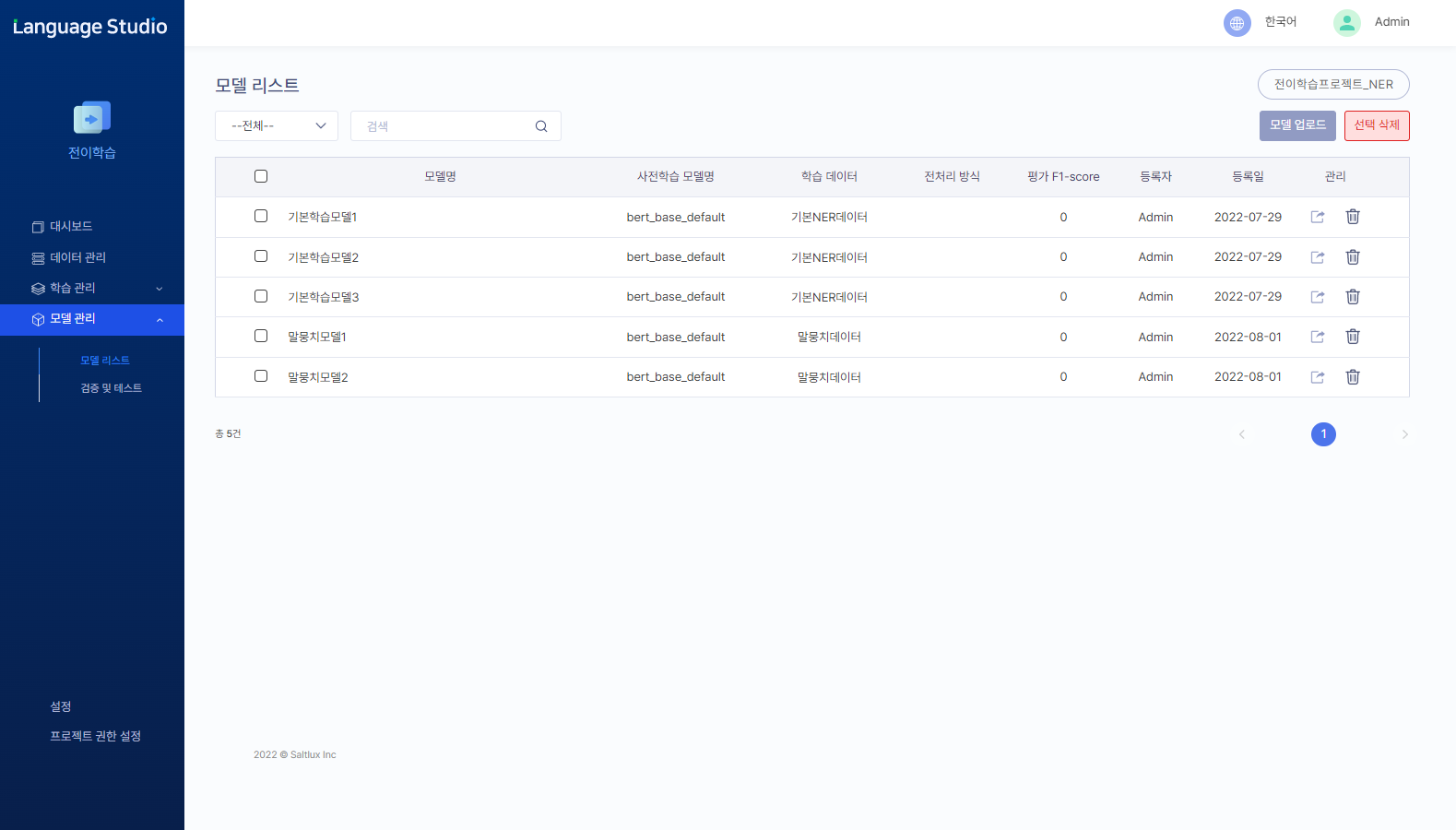
03Model arrangement and management
-
Integrated management from model creation, arrangement to application
- Fully trained domain models optimized for domain
- Use a variety of cloud arrangement techniques to launch models instantaneously
- Web-based model management
- GUI-based process for model creation, learning, and evaluation
-
-
-
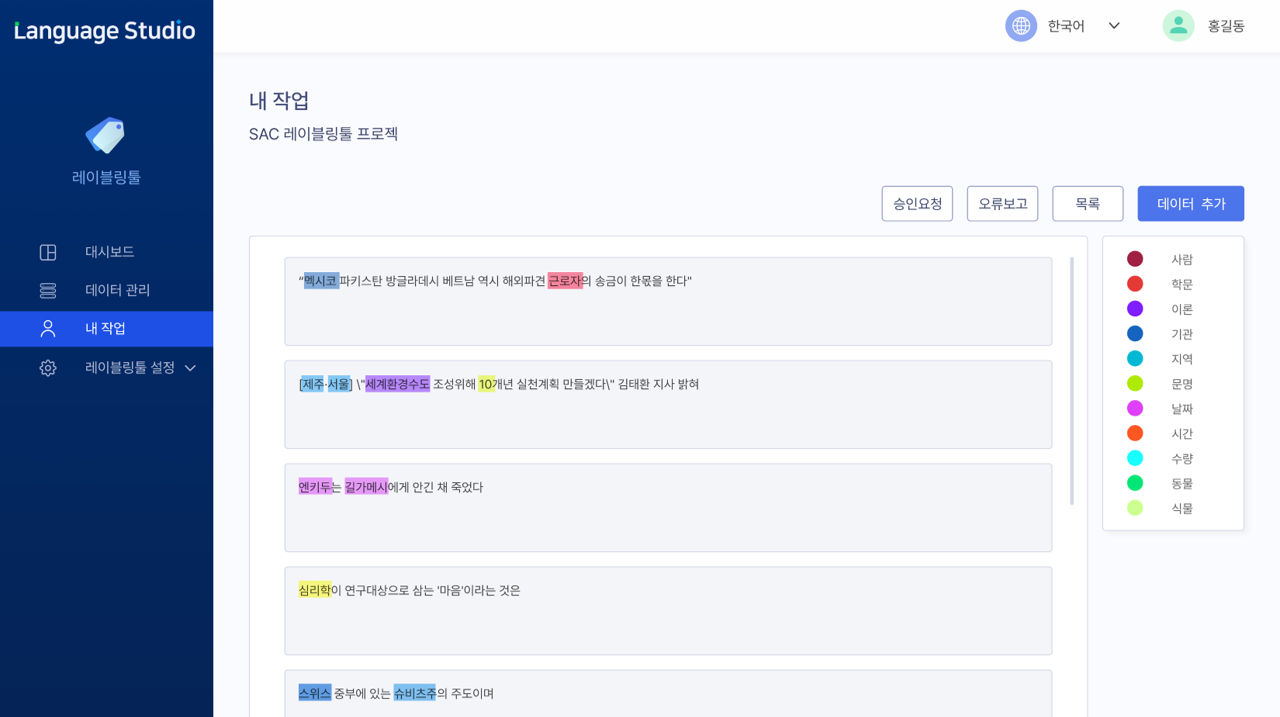
04Labeling tool (option)
-
Web-based annotation
- Customize data for a variety of issues
- Support simultaneous operation for collaboration among multiple domain experts
- Inspect data annotation
- Download final delivery as JSON file
-
-
Use Case
LANGUAGE STUDIO creates new value by converging with various solutions.

Success Story
-
KMS analysis and knowledge-to-data
Samsung Electronics Mosaic, a collective intelligence platform
Established a comprehensive knowledge management system for the overall technology process, network, and technology analysis trends for KMS information and opinion that are registered internally.
-

- Improved knowledge productivity and work efficiency through analysis and knowledge transfer of registered Samsung Electronics' KMS documents.
- 5 times more users compared to the existing system
-
Integrated VOC system
Hanwha Group integrated VOC analysis system
Internal and external data collecting systems for each subsidiary were built using the VOC and big data analysis system, and via the analysis of VOC, a CS management support and customer support monitoring system were established.
-
- To improve Hanwha Group's management of its VOC resources, a methodical collecting procedure was established through the VOC analysis system, and the VOC analysis was carried out in accordance with user demands.
-
News analysis system
Advanced Korea Press Foundation media content analysis system
Project to enhance the system that makes data production relatively easy by refining the platform which has vast amount of news data
-
- Established a foundation for systematic analysis of global news data
- Enhanced quality of language analysis through improved management tools and language resource purification
- Improved user convenience by improving web service quality
Reference
-
Intelligent integrated search
Constitutional Court
A simple semantic based precedent retrieval method using daily terminology

-
New technology sensing
Samsung Electronics
Knowledge management system with extensive R&D trend signal detection

-
Incomplete sales
Nonghyup Card
Monitoring of outbound incomplete sales and consultation analysis report

-
Analysis of call center consultation topics
Nonghyup Bank
Analysis of positive/negative feedback on call center consultation

-
KT VOC system
KT
Customer VOC analysis, reports and insights on KT telecommunication products

-
VOC analysis system
Korea Expressway Corporation
Continuous monitoring system for customer complaints through atypical VOC analysis

-
Top 2020 Digital New Deal practices
Korean dialect AI dataNational Information society Agency
15,000 hours of learning data, transcription of 2.5 million sentences of regional dialect

-
2020 Daily Conversation Corpus
National Institute of Korean Language
Transcription corpus by recruiting more than 2,000 speakers from each region

-
AI data for in-depth interviews in specialized fields
National Information society Agency
Learning data from in-depth expertise interviews covering more than 2,000 hours
-
Korean corpus research
National Institute of Korean Language
5.5 million separate words of spoken language in the corpus of the foundational study on contemporary language.
-
Large-scale Korean corpus
National Information society Agency
Online colloquial learning data based on a total of 2 billion words of web data
-
Spoken language corpus
National Institute of Korean Language
15,000 hours of broadcast conversations, establishing about 15.4 million raw corpus